Build a Question Answering application over a Graph Database
In this guide we'll go over the basic ways to create a Q&A chain over a graph database. These systems will allow us to ask a question about the data in a graph database and get back a natural language answer.
⚠️ Security note ⚠️
Building Q&A systems of graph databases requires executing model-generated graph queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent's needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, see here.
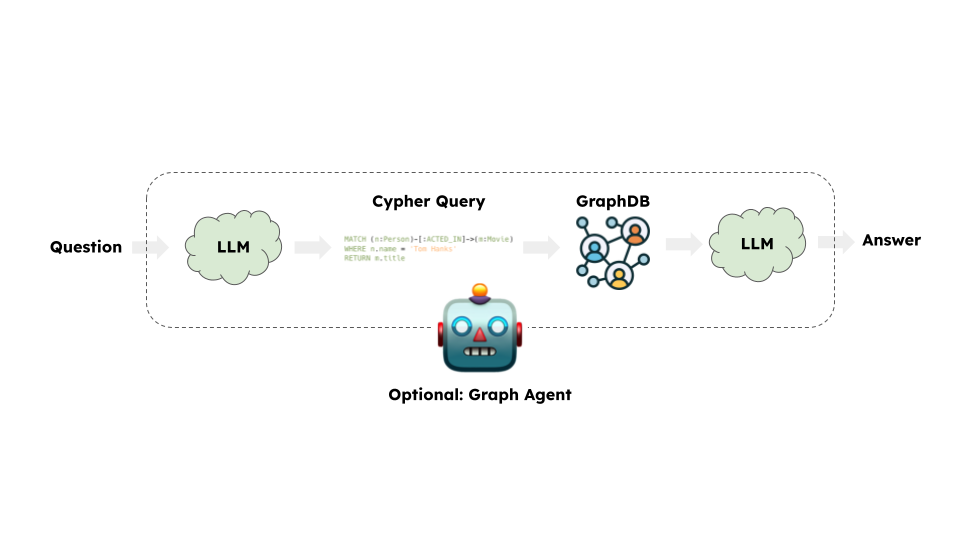
Architecture
At a high-level, the steps of most graph chains are:
- Convert question to a graph database query: Model converts user input to a graph database query (e.g. Cypher).
- Execute graph database query: Execute the graph database query.
- Answer the question: Model responds to user input using the query results.
Setup
First, get required packages and set environment variables. In this example, we will be using Neo4j graph database.
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
We default to OpenAI models in this guide.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
········
Next, we need to define Neo4j credentials. Follow these installation steps to set up a Neo4j database.
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# Import movie information
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
[]
Graph schema
In order for an LLM to be able to generate a Cypher statement, it needs information about the graph schema. When you instantiate a graph object, it retrieves the information about the graph schema. If you later make any changes to the graph, you can run the refresh_schema method to refresh the schema information.
graph.refresh_schema()
print(graph.schema)
Node properties are the following:
Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING},Genre {name: STRING},Chunk {id: STRING, question: STRING, query: STRING, text: STRING, embedding: LIST}
Relationship properties are the following:
The relationships are the following:
(:Movie)-[:IN_GENRE]->(:Genre),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)
Great! We've got a graph database that we can query. Now let's try hooking it up to an LLM.
Chain
Let's use a simple chain that takes a question, turns it into a Cypher query, executes the query, and uses the result to answer the original question.
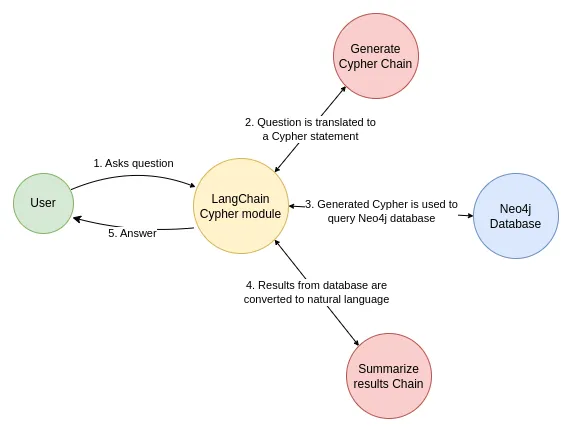
LangChain comes with a built-in chain for this workflow that is designed to work with Neo4j: GraphCypherQAChain
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True)
response = chain.invoke({"query": "What was the cast of the Casino?"})
response
[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mMATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name[0m
Full Context:
[32;1m[1;3m[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}][0m
[1m> Finished chain.[0m
{'query': 'What was the cast of the Casino?',
'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
Validating relationship direction
LLMs can struggle with relationship directions in generated Cypher statement. Since the graph schema is predefined, we can validate and optionally correct relationship directions in the generated Cypher statements by using the validate_cypher parameter.
chain = GraphCypherQAChain.from_llm(
graph=graph, llm=llm, verbose=True, validate_cypher=True
)
response = chain.invoke({"query": "What was the cast of the Casino?"})
response
[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mMATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name[0m
Full Context:
[32;1m[1;3m[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}][0m
[1m> Finished chain.[0m
{'query': 'What was the cast of the Casino?',
'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
Next steps
For more complex query-generation, we may want to create few-shot prompts or add query-checking steps. For advanced techniques like this and more check out:
- Prompting strategies: Advanced prompt engineering techniques.
- Mapping values: Techniques for mapping values from questions to database.
- Semantic layer: Techniques for implementing semantic layers.
- Constructing graphs: Techniques for constructing knowledge graphs.